3. Policy Gradient
Q. Why do we use Action-value function over State-Value function in Model Free reinforcement learning

Q. 위에서 Action-value function Q를 업데이트 할 때 total discounted return Gt를 Q를 이용해 근사한다.
State-value function V와 Q 모두 앞으로의 기대되는 return에 대한 함수이지만 해당 state에서 얻을 수 있는 return인지, 해당 state와 어떤 action에서 얻을 수 있는 return 인지에 대해 차이가 있다.
이 때, V에서 샘플링할 수 없을까? 왜 model-free에서는 V보다 Q가 필요할까?
A. Model-free 접근 방식을 사용하여 주어진 policy에 대한 State-value function V를 학습할 수 있다. 하지만 학습한 V를 사용하여 action을 선택할 수는 없다.
그 이유는 action에 따라 다음에 어떤 state가 발생할지 예측할 방법이 없기 때문이다. 이는 모두 action 값을 사용해야 하는 몬테카를로(Monte-Carlo) 제어, SARSA 및 Q-러닝과 같은 경우에서 문제다. Actor-Critic 방법에서와 같이 policy gradient와 결합하면 별도의 제어 가능한 policy을 제공하기 때문에 문제가 되지 않는다.
RL Agent Taxonomy
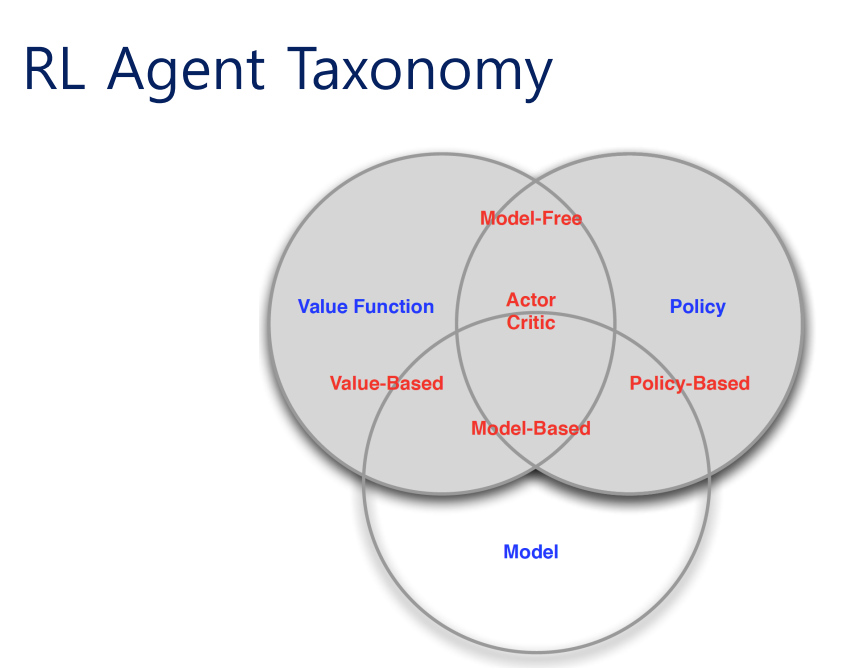
RL 알고리즘에는 아래와 같은 종류가 있다.
- Policy gradients: 에 대해 미분하여
- REINFORCE
- Natural policy gradient
- Trust Region Policy Optimization (TRPO)
- Value-based RL: 최적 policy의 value function이나 Q-function을 추정
- Q-learning, DQN
- Temporal Difference Learning
- Fitted value iteration
- Actor-critic RL: 현재 policy의 value function이나 Q-function을 추정하여 policy 개선에 사용
- Asynchronous advantage actor-critic (A3C)
- Soft Actor-Critic (SAC), DDPG
- Model-based RL: transition model을 추정하여 planning에 사용하거나 policy 개선에 사용
- Dyna
- Gaussian Process dynamic programming / PILCO (https://mlg.eng.cam.ac.uk/pub/pdf/DeiRas11.pdf)
Model-based algorithms
Diagram
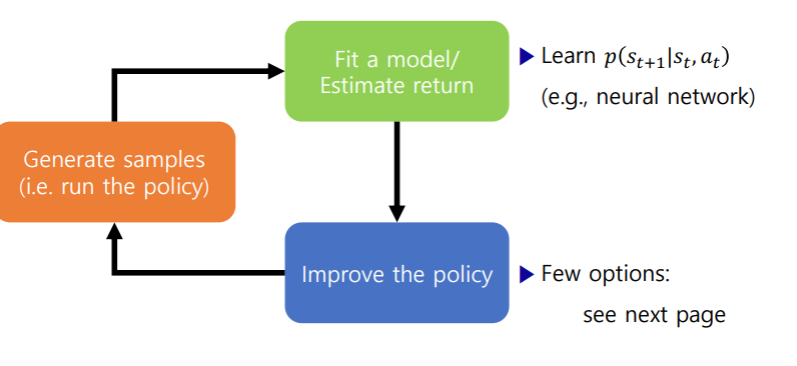
Policy를 개선하기 위한 몇가지 옵션
- Model를 이용한다(policy X)
- 경로 최적화 혹은 최적 제어한다
- Discrete action spaces 에서 planning한다.( e.g. Monte Carlo tree search)
- Policy의 gradient로 역전파(backpropagate)하기
- 연속적인 최적화 방식을 사용
- numerically unstable 하기 때문에 약간의 trick이 필요하다
- Value function을 학습하기 위해 model을 사용한다
- Dynamic programming
- Generate simulated experience for model-free learner
Question
- 위의 내용들이 어떤 뜻인지 제대로 이해 못함
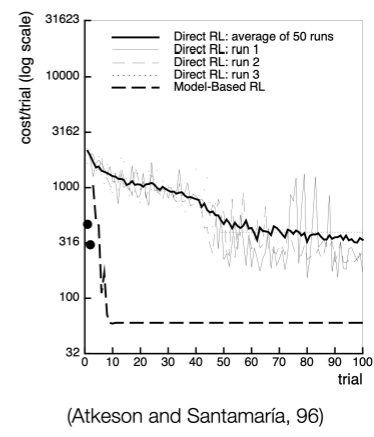
Model-based RL은 데이터로부터 MDP를 추정한다. 따라서 데이터를 효율적으로 사용하지만 복잡한(high-demensional) state space에서는 좋지 않다.
Value function-based algorithms
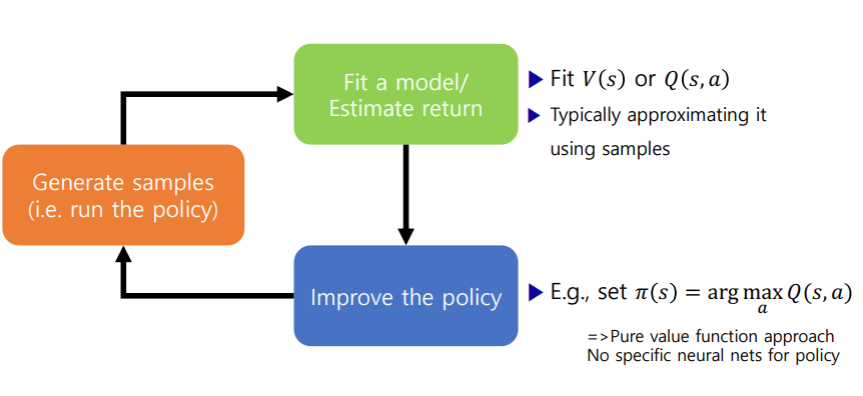
- Learnt value function
- Implicit policy (e.g. - greedy)
- Examples
- Q-learning, DQN
- Temporal Difference Learning
- Fitted value iteration
Direct policy gradients
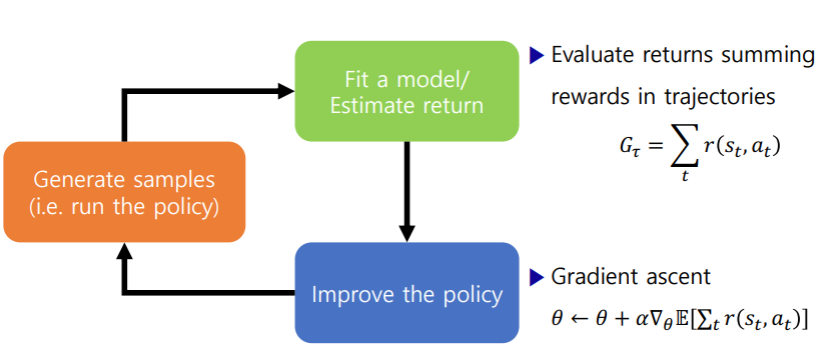
Policy based에는
- No value function
- Learnt policy
- Examples
- REINFORCE
- Natural policy gradient
- Trust Region Policy Optimization (TRPO)
Actor-critic: value functions + policy gradients
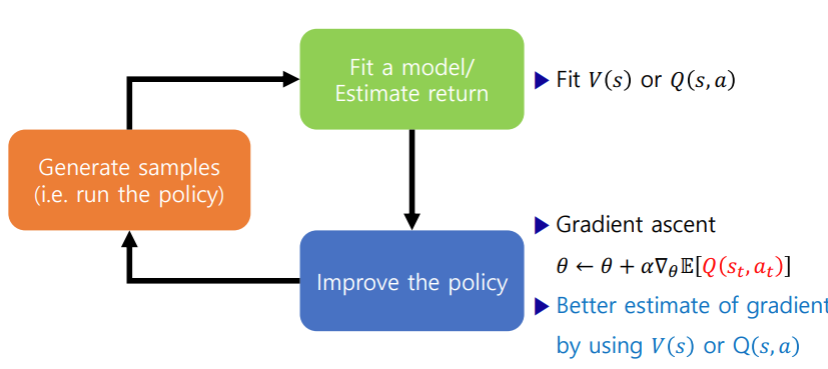
- Learnt value function
- Learnt policy
- Examples
- Asynchronous advantage actor-critic (A3C)
- Soft Actor-Critic (SAC), DDPG
왜 이렇게 많은 알고리즘들이 있는 걸까?
-
다른 tradeoffs
여러 문제들이 있기 때문에 각각의 문제에 더 나은 방법들이 다르다.
- Sample efficiency: 좋은 policy를 얻기 위해 얼마나 많은 sample들이 필요한지
- 알고리즘이 off policy인지 on policy인지에 따라 다르다.
- Off policy: 새로운 샘플들을 만들지 않고도 policy를 개선할 수 있다.
- On policy: 매번 policy가 바뀌기 때문에 새로운 sample을 만들어야 한다.
- 알고리즘 별로 비교
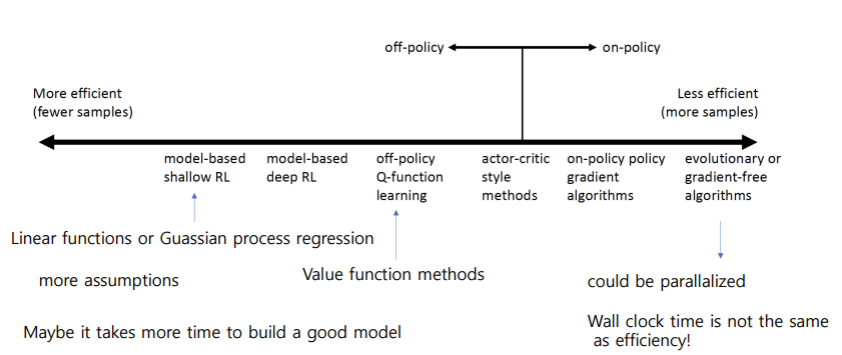
- 효율적이고 적은 샘플로도 충분할 수록 많은 가정이 필요하다.(때로는 좋은 모델을 얻기 위한 시간이 더 필요할 수 있음.)
- Stability & easy of use
- Sample efficiency: 좋은 policy를 얻기 위해 얼마나 많은 sample들이 필요한지
-
Different assumptions
문제에 대한 가정들이 다르다.
- Stochastic or deterministic?
- Continuous or discrete?
- Episodic of infinite horizon?
-
Different things are easy or hard in different settings
각각이 가진 장단점(1번이랑 유사)
- Easier to represent the policy?
- Easier to represent the model?
On-Policy Control with SARSA
SARSA는 State-Action-Reward-State-Action의 약자로 on-policy TD control method이다.

Policy improvement에는 - greedy 방식을 사용한다. 이를 통해 Action을 선택하고 이를 반복한다.
Off-Policy Control with Q-Learning
behaviour, target policies를 모두 improve 하지 않는 것은 off-policy 방식이다.
Q-learning은 SARSA와 유사하지만 policy를 이용해 다음 action을 선택하기 보다 greedy한 방식을 취한다.

위의 SARSA pseudocode와 비교해보면 Action을 update하지 않는다. 대신 policy로부터 계속 Action을 선택한다.
Policy Gradient
큰 MDP문제를 푸는 것의 문제는 너무 많은 state와 action을 저장하고 있어야 하는 것과 각각의 state에 대해 학습하는 것이 너무 느리다는 것이다.
이를 해결하기 위해
- function approximation을 이용해 value function을 추정한다.
- 관찰된 state를 통해 관찰되지 않은 state들을 generalize한다.
- MC나 TD 방식을 통해 를 업데이트 한다.
Function approximation에는 여러 방법이 있다.
- Linear combinations of features
- Neural network
- Decision tree
- Nearest neighbour
- Fourier / wavelet basis
그리고 미분가능한 종류들을 고려한다면 Linear combinations of features, NN 그리고 Gaussian process가 있다.
Advantages of Policy-Based RL
앞서 Policy-based RL에 대해 간략히 알아보았다. 이 Policy-based RL의 장단점은 아래와 같다.
Advantages
- 나은 수렴성
- high-dimensional이나 continuous한 action space에서 효율적이다
- Stochastic policy를 학습할 수 있다. (??)
Disadvantages
- local optimum으로 수렴할 가능성이 높다
- policy evaluation이 비효율적이다.
Policy Optimization
Policy-based RL은 최적화 문제이다(an optimization problem)
이러한 문제를 푸는 방식에는 종류가 여러가지 있다.
Gradient를 사용하지 않는 방식에는
- Hill climbing
- Simplex / amoeba / Nelder Mead
- Genetic algorithms
Gradient를 사용하면 주로 효율적이다
- Gradient ascent
- Conjuage gradient
- Quasi-newton