Learning high-speed flight in the wild
DOI: 10.1126/scirobotics.abg5810
이 논문은 러닝 기법을 활용한 드론 비행의 시초가 되는 논문으로 Imitation learning (IL) 기법을 활용하여 end-to-end 로 여러 환경에서 비행함을 보였다. End-to-end planning 은 센서 input 에서 바로 trajectory 를 output 을 내보내는 것을 의미한다.
기존의 자율 비행 시스템은 Sensing → Mapping → Planning 의 순차적인 파이프라인에 의존하여, 처리 지연(latency)과 누적 오차 문제로 고속 주행에는 한계가 있었다.
본 논문에서는 시뮬레이션 내에서 ground-truth 환경 정보에 접근할 수 있는 expert 를 모방하는 방식으로 학습을 진행하고 end-to-end 방식을 통해 기존의 문제를 해결하고자 하였다.
또한, 다양한 시뮬레이션 환경을 통해 zero-shot transfer 능력을 보이고 이를 여러 실제 환경에서 검증하였다.
Method
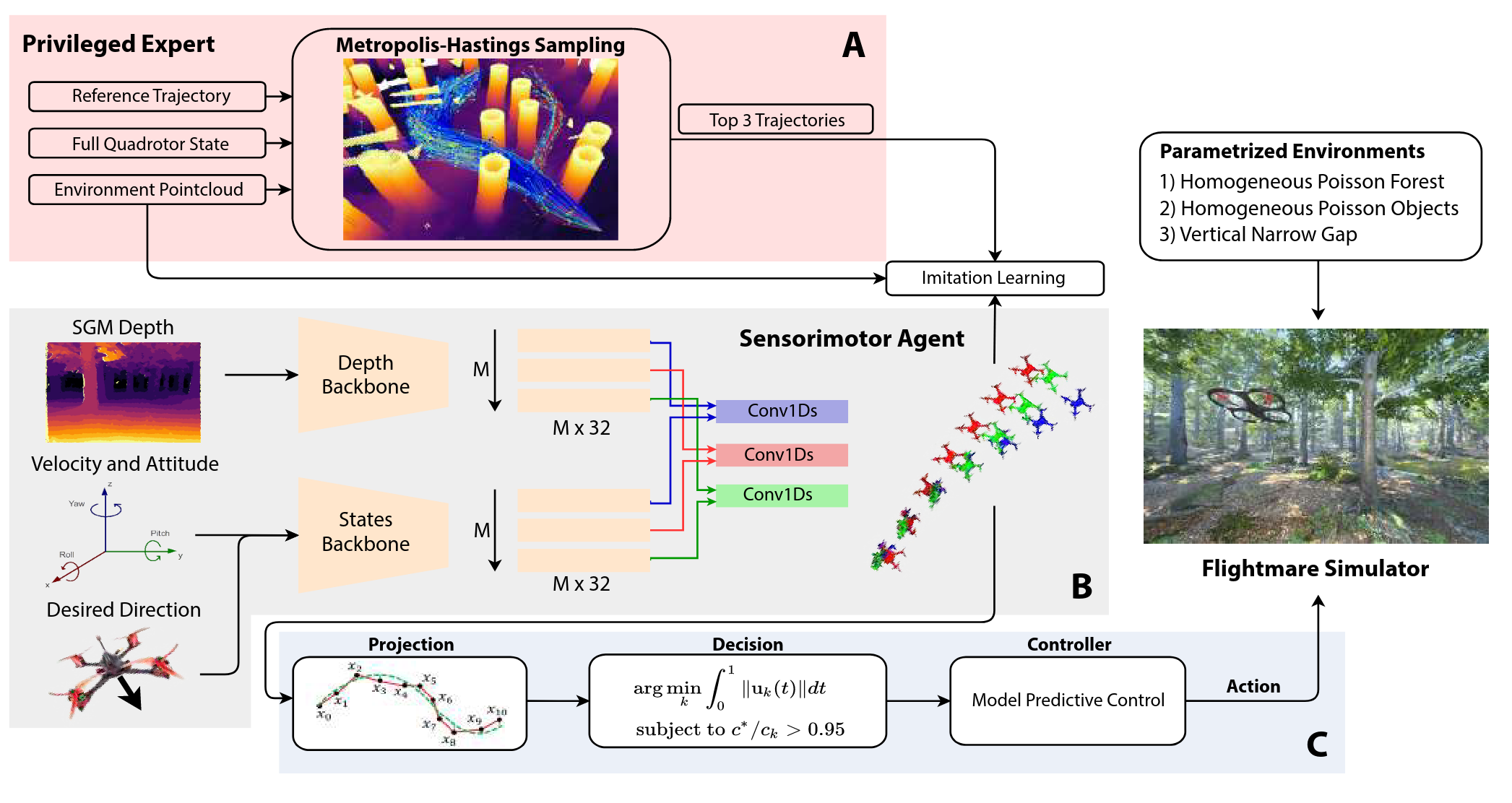
본 연구의 시스템은 Privileged Learning 이라고 하는 일종의 imitation learning (IL) 을 기반으로 한다. 시뮬레이션 환경에서 모든 정보(3D 지도, 드론의 정확한 상태)에 접근할 수 있는 Privileged expert (Teacher) 가 생성한 최적의 궤적을, 제한된 센서 정보(depth 이미지, IMU)만을 가진 Sensorimotor agent (Student) 가 모방하도록 학습함.
위 그림 모듈을 A → C 순서로 설명.
(A) Privileged Expert
설명한대로 privileged expert 는 state 와 environment 에 대해 정확한 정보를 알고 있고, 여러 개의 collision-free 한 궤적 를 생성한다.
이를 위해 장애물과의 거리와 reference trajectory 와의 유사성이 고려된 확률분포 에서 샘플링을 수행한다.
즉, 의 확률분포는 장애물로 부터 멀고, 와 가까울 수록 크다. 여기서 는 environment 의 point cloud 이고, 는 정규화 항이다.
비용 함수 는 아래와 같이 정의된다.
설명한 대로 장애물과의 거리와 와의 유사성을 목적함수로 한다. 샘플링에는 M-H algorithm 을 사용하였고 는 cubic B-spline 으로 하였다고 한다. 그래서 궤적 전체를 샘플링 하지 않고 control points 를 sampling 해서 궤적을 생성하고 이를 MPC 로 tracking 하였다고 한다.
구체적인 사항은 논문을 참고하기 바람.
를 생성할 때는 Liu et al. 을 사용했다고 한다.
(B) Sensorimotor Agent
Student policy 는 on-board 에서의 센서값만 가지고 실시간으로 collision-free trajectory 를 만들어야 한다.
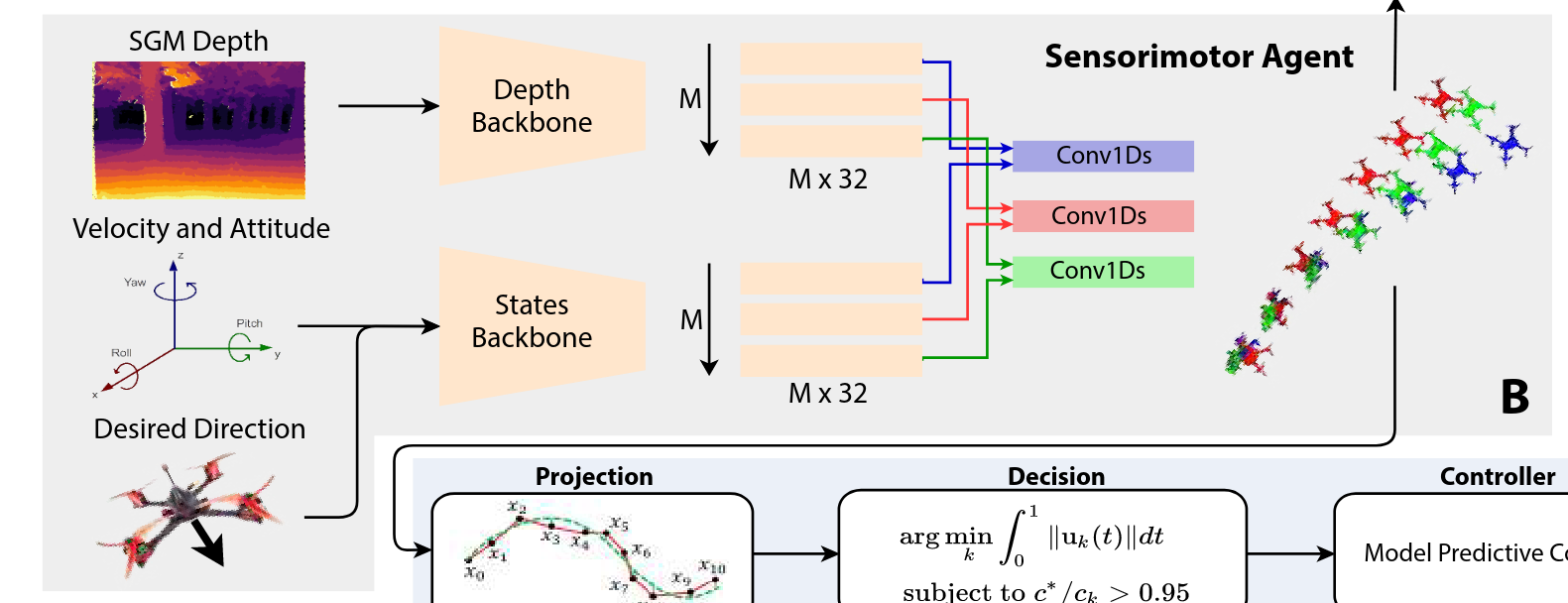
모델 구조는 위 그림 참고.
우선 Stereo Semiglobal Matching (SGM) 방법으로 얻어진 depth 이미지를 포함한다. 그리고 이들은 각각 encoder 를 통해 feature vector 를 얻고, 이를 1D convolution 을 통해 각각의 modality 를 갖는 trajectory 를 얻는다.
본 논문에서는 로 하여 3개의 궤적이 나올 수 있도로 ㄱ하였고, depth 이미지를 위한 네트워크는 pre-trained 된 MobileNet-V3 을 사용하였다.
그래서 최종적으로는 궤적 와 그의 collision cost 가 나오게 된다. 따라서 output 은 a set 의 궤적이 된다. (i.e. )
앞선 teacher policy 와 다르게 위치값의 벡터 형태로 표현된다.
학습은 expert policy 에 의해 얻은 3개의 궤적을 바탕으로 supervised learning 을 한다.
여러 개의 예측값에 대해 학습하기 때문에 본 논문에서는 Relaxed Winner-Takes-All (R-WTA) loss 를 사용하였다.
은 각각 expert 와 network 의 궤적을 의미한다. 은 아래와 같이 정리된다.
위의 수식은 예측과 라벨 간의 하드 할당(hard assignment)을 수행하므로 미분 불가능하다.
따라서, 본 논문은 gradient descent로 최적화하기 위해 작은 값의 을 사용해 할당을 relax 한다. 이를 위해 과 같은 수식이 나오게 되었다. 이렇게 되면, 가장 가까운 예측값에는 , 나머지에는 만큼의 작은 weight를 줘서 부드러운 loss를 구성할 수 있다.
또한, 예측된 collision cost 을 grount-truth cost 통해 학습하고자 하여 최종적인 training loss 는 아래와 같다.
이 이후에는 얻어진 로 polynomial 궤적을 만들고, 가장 collision cost 가 낮은 것을 선택해 MPC 로 tracking 한다.
(C) Training Environments
본 논문에서는 Flightmare 시뮬레이터를 사용하였고, forest 환경이나 convex shapes 의 장애물들이 random 하게 생성된 환경에서 학습을 하였다고 한다.
자세한 시뮬레이션 환경과 학습 디테일들은 논문 참고.
Experiments & Results
A. High-Speed Flight in the Wild
학습에 사용되지 않은 다양한 실제 환경(숲, 눈 덮인 산길, 폐건물, 열차 사고 현장 등)에서 Zero-shot 성능을 검증했다.
성능은 최대 10 m/s (36 km/h) 의 평균 속도로 비행하며 성공적으로 장애물을 회피했음.
여러 환경과 실험 세팅에서 성능을 보였기 때문에 자세한 사항은 본 논문을 직접 확인하면 좋을 듯.
B. Controlled Experiments in Simulation
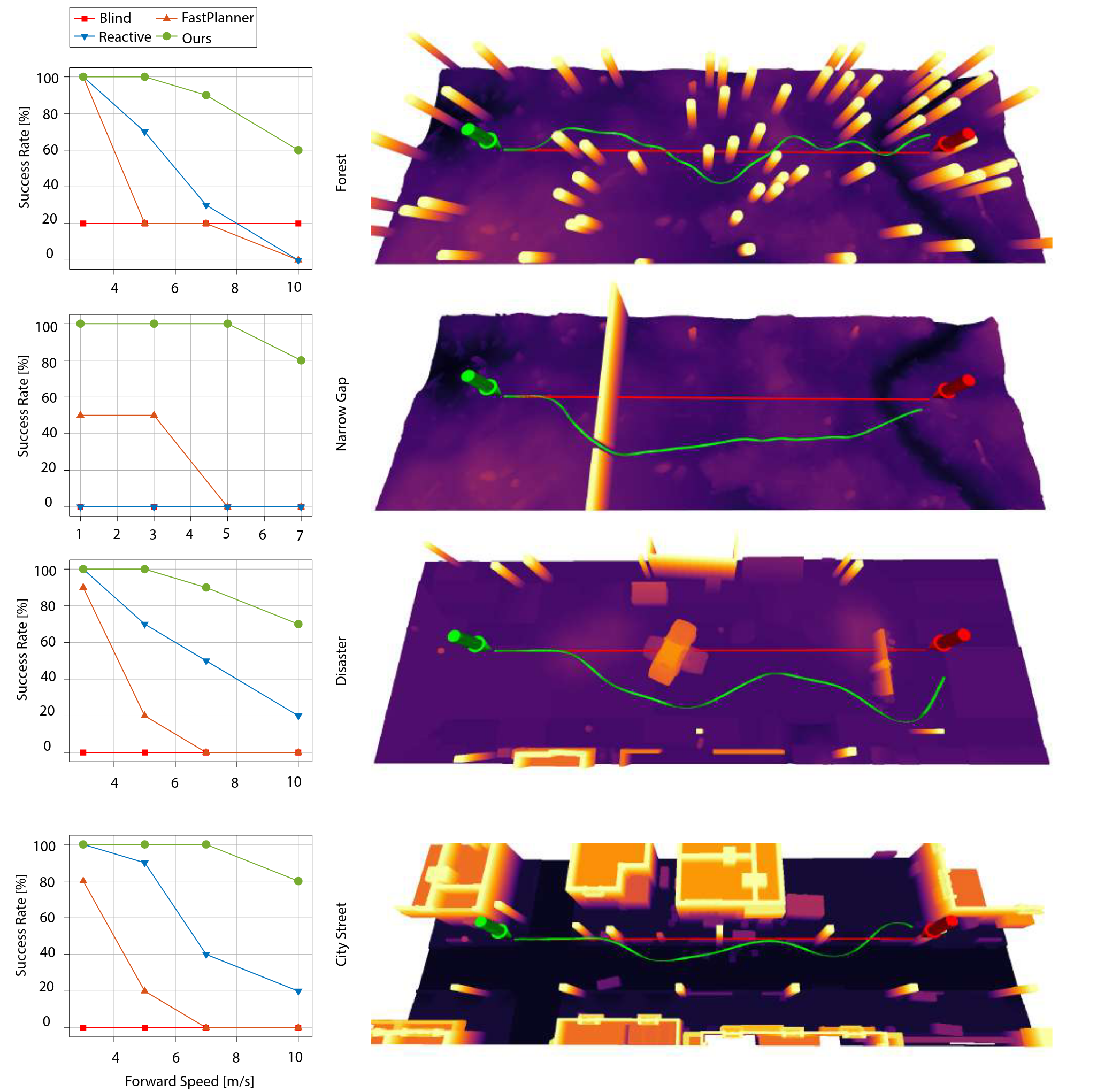
- 비교 대상:
Baselines
[18, FastPlanner] B. Zhou, F. Gao, L. Wang, C. Liu, and S. Shen, “Robust and efficient quadrotor trajectory generation for fast autonomous flight,” IEEE Robot. Autom. Lett., vol. 4, no. 4, pp. 3529–3536, 2019. [32, Reactive] P. Florence, J. Carter, and R. Tedrake, “Integrated perception and control at high speed: Evaluating collision avoidance maneuvers without maps,” in Algorithmic Foundations of Robotics XII. Springer, 2020, pp. 304–319.
전반적으로 저속인 3 m/s 에서는 모든 방법이 유사한 성능을 보였지만, 속도가 증가할수록 기존 방법들의 성공률은 급감함. 제안된 방법은 10 m/s의 고속에서도 70% 의 평균 성공률을 기록하고, 모든 환경에서 우수한 성능을 보임.
C. Computational Cost
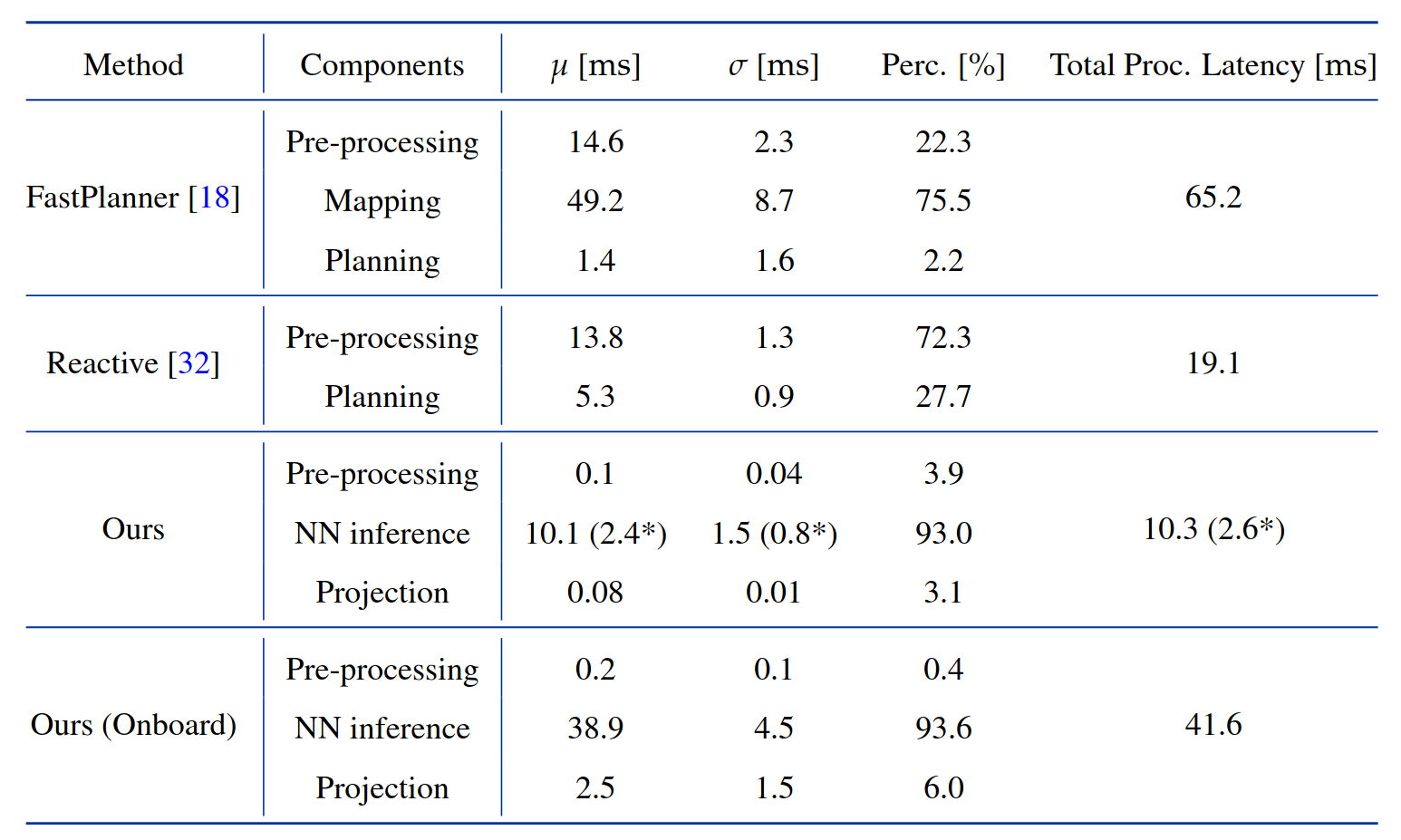
위 표는 기존 플래닝 방식들 (최적화 기반, mapless 방식) 과 비교하여 각 pipeline 별로 processing latency 가 어떻게 되는지 보여준다.
제안된 방법은 Jetson TX2에서 센서 입력부터 행동 명령까지 약 41.6ms 가 소요되어 24Hz 의 업데이트가 가능함을 보였다.
이는 데스크탑 컴퓨터에서 측정한 FastPlanner (65.2ms) 보다 훨씬 빠르며, 전반적으로 end-to-end planning 방법의 우수성을 보였다.
D. The effect of latency and sensor noise
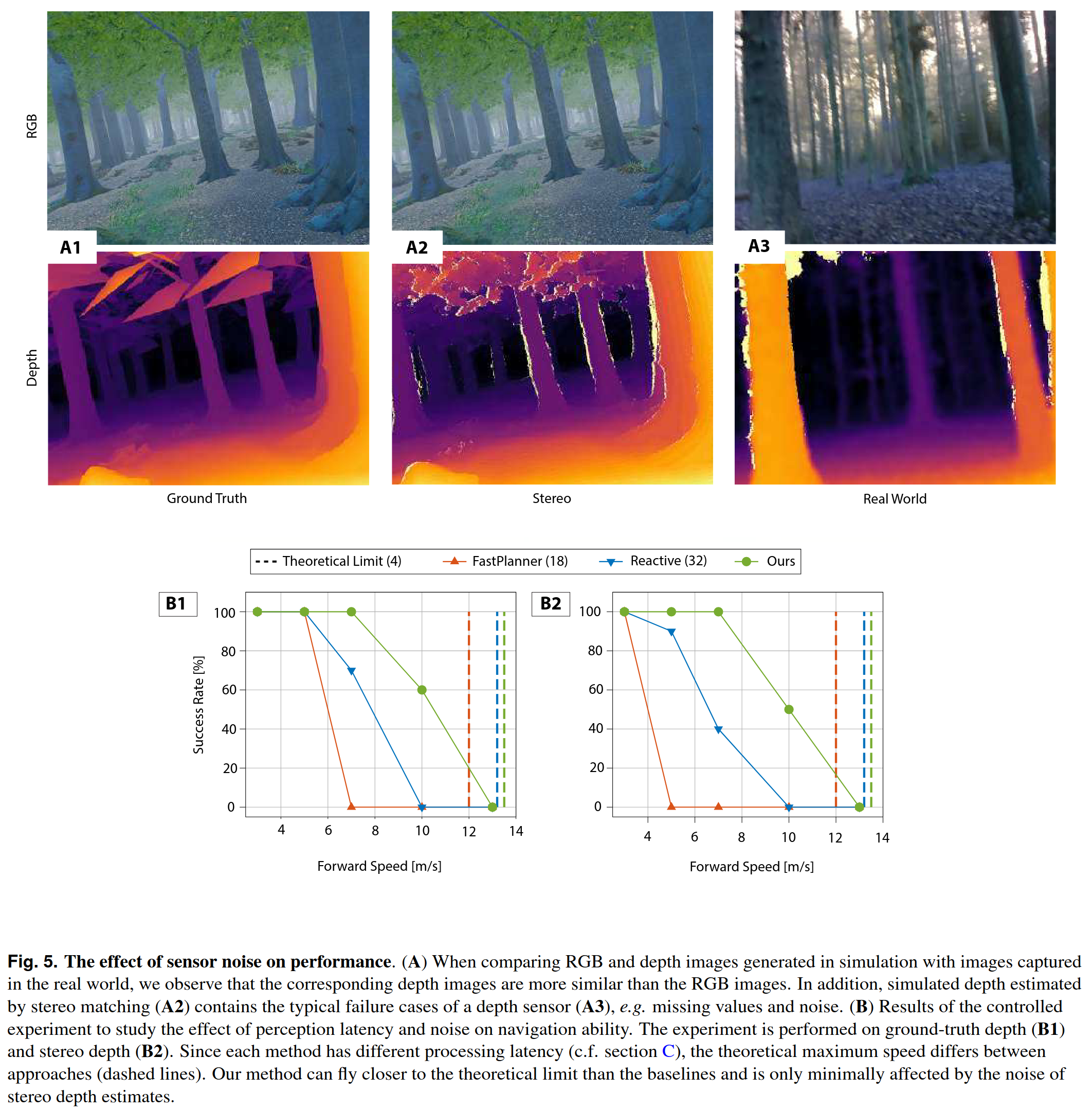
첫 번째로, 본 논문에서는 RGB 대신 depth 이미지를 학습에 사용하였다. Fig. 5 의 A 를 보면 알겠지만, depth 가 Ground Truth, Stereo, Real World 간의 차이가 더 적어보임을 알 수 있다.
그리고 시뮬레이션에서 센서 노이즈가 없는 조건과 실제와 유사한 노이즈가 있는 조건에서 실험을 비교했다.
기존 방법들은 센서 노이즈가 추가되자 성능이 크게 하락했지만, 제안된 방법은 성능 저하가 미미하고 B1, B2 간의 성능 그래프가 유사하게 나타남을 알 수 있다. 이는 학습 과정에서 의도적으로 노이즈가 포함된 depth 이미지를 사용했기 때문이다.
Conclusion & Discussion
본 논문은 드론 분야에서 Privileged Learning 을 통해 학습된 End-to-End policy 로, 드론의 고속 자율 비행을 최초로 보인 논문이다. 그래서 본 논문 이후로 여러 로보틱스 분야에서 end-to-end 기법을 적용한 (자율주행 제외) 방법론이 등장하고 RL, Imperative learning 등이 등장하였다.
주요 기여:
- End-to-End 고속 비행: 감지부터 제어까지의 과정을 하나의 신경망으로 통합하여 고속 비행에 필수적인 낮은 지연 시간을 달성.
- Sim-to-Real Zero-Shot Transfer: 사실적인 센서 시뮬레이션을 통해 시뮬레이션에서만 학습하고도 실제 세계에 바로 적용 가능함을 보임.
- SOTA 성능: 기존 최신 기술들을 훨씬 능가하는 비행 속도와 성공률을 복잡한 환경에서 달성.