Lecture 1. Introduction - Lecture 2. Imitation Learning Part 2
Lecture 1. Introduction
https://rail.eecs.berkeley.edu/deeprlcourse/deeprlcourse/static/slides/lec-1.pdf
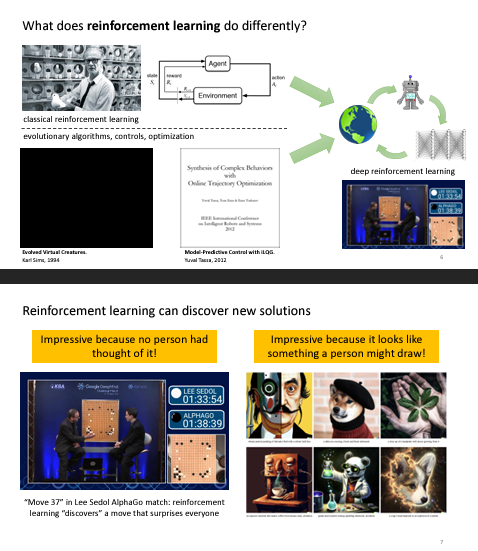
RL 과 제어, 최적화를 결합하여 딥러닝 방식의 강화학습은 사람에 의해 수행되는 최근의 AI (Generative AI) 보다 완전히 새로운 해답 / 방식을 찾아낼 수 있다.
강화학습이 다른 머신러닝과 다른점
기존 머신러닝(supervised) 는 정답지가 있는 데이터셋을 가지고 input에 대한 정답을 얻어내는 함수를 찾는 것
강화학습은 정답지 대신에 보상 개념을 이용해 성공적으로 어떠한 목적을 수행할 수 있게 한다.
결론적으로, 최대의 보상( return )을 얻을 수 있는 일련의 행동( action )을 선택하는 함수( policy )를 찾는 것
강화학습을 배워야 하는 이유?
위에서 처럼 새로운 해답이나 접근을 찾아낼 수 있다. 데이터를 이용한 AI 들은 인간보다 더 잘하기는 힘들다(의미적으로). 주어진 데이터에서 잘 하는 것이 최선이다.
RL은 대신에 목적을 찾아내는데 집중하기 때문에 최적화와 관련있다.
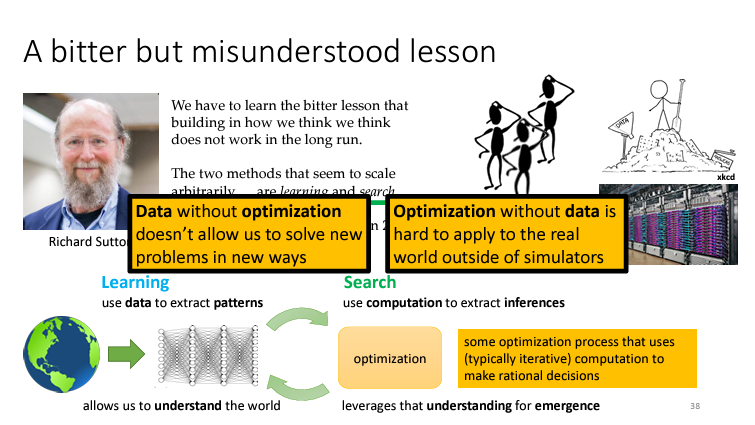
그래서 R.Sutton 의 말대로 Learning으로 데이터를 이용해 우리가 보는 방식과는 다를 수 있지만 환경을 이해할 수 있게 해주고 이해한 내용을 바탕으로 Search을 수행해야 할 것이다. (data + optimization )
Reward 를 어떻게 할 것인가
잔에 있는 물을 따르는 것 처럼 인식이 어려운 문제도 있지만, 아주 긴 시간 동안 한 두번 밖에 이루어지지 않는 보상들 (졸업, 취직 등등)은 적절하게 설정하기도 어렵고 이후에 과정에서 보상이 이루어지는 경우가 많다.
또, 동물들 같은 경우는 여러 시도를 통해 사냥을 배우는 것이 아니라 본능적 혹은 다른 동물들을 관찰하며 사냥법을 습득한다.
그래서 최근에는 Imitation Learning 이나 Inverse Learning 기법들을 사용한다.
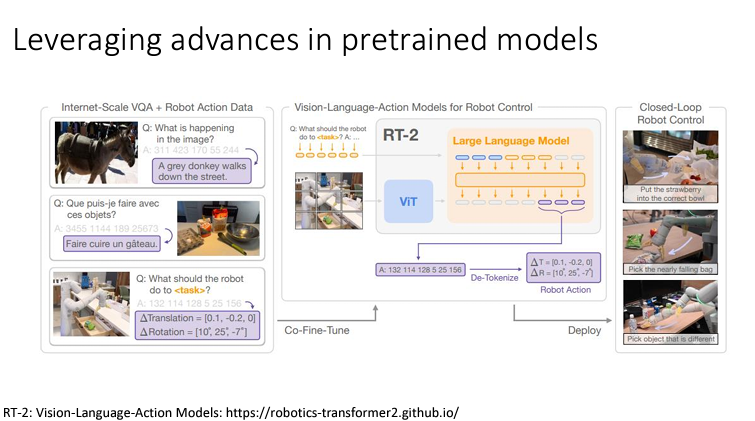
최근에 많이 발전한 Pre-train 모델을 사용하기도 한다. LLM 을 통해 이미지를 처리하고 이를 통해 얻은 지식을 로봇에 넣어준다.
남아있는 Challenges
많은 데이터를 학습시키는 방법과 RL을 사용하는 방식 모두 근래의 많은 연구가 진행되었지만, 데이터와 RL 을 모두 사용하는 혁신적인 구조는 아직 없음.
deep RL 은 보통 느리고 보상함수나 예측이 어떤 방식이어야 하는지 아직 명확하지 않다.

Lecture 2. Imitation Learning
https://rail.eecs.berkeley.edu/deeprlcourse/deeprlcourse/static/slides/lec-2.pdf
Supervised Learning of Behaviors
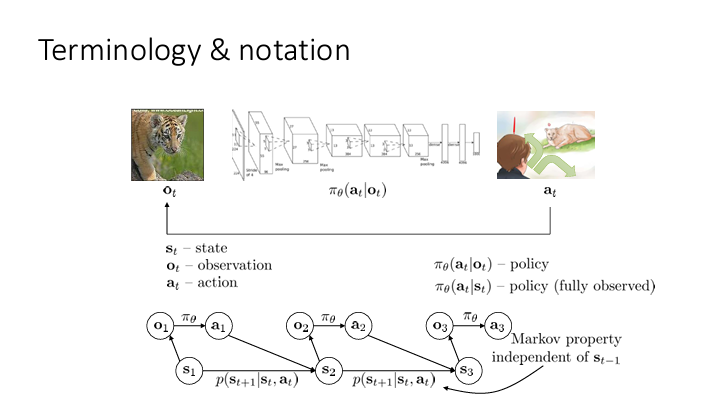
보통 observation 과 state 를 혼용하여 사용하지만 state 는 해당 시점에서의 모든 정보를 포함하고 있는 쪽에 가깝고 observation 은 그러한 state 에서 얻을 수 있는 정보로 구분해야 한다.
그림에서의 는 observation 로부터 어떠한 action 를 선택하게 하는 policy 이다.
Markov property 에 의해 는 까지에 모든 정보를 담고 있다고 가정한다.
Imitation Learning
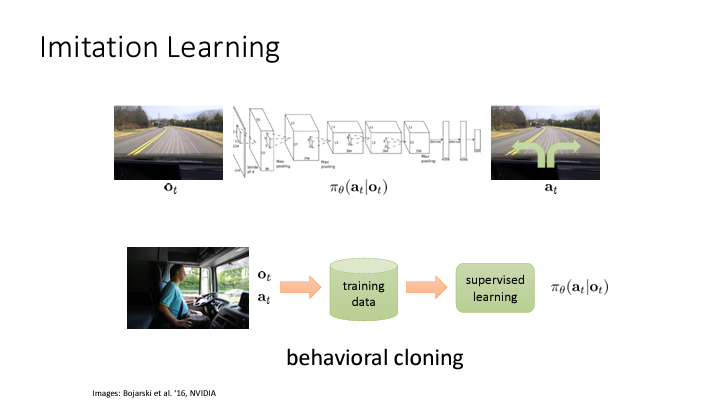
전문가의 행동을 기반으로 보상함수를 설정하여 policy 를 찾는 방법
ALVINN: https://proceedings.neurips.cc/paper/1988/file/812b4ba287f5ee0bc9d43bbf5bbe87fb-Paper.pdf
하지만 이러한 방식은 쉽게 실패한다. 시간이 지남에 따라 잘못된 선택 ( mistakes ) 가 누적되기도 하고, 어떤 범위까지 전문가의 행동을 모방해야 하는지 모호하고 변칙적인 상황에 취약하다.
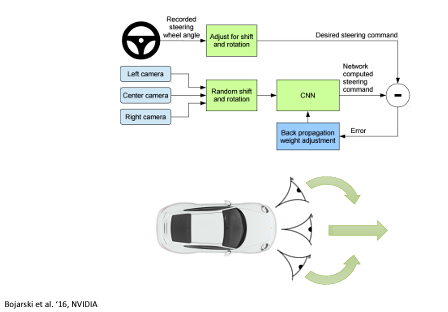
supervised learning 에서는 이러한 성향이 나타나지 않는다. 3 개의 카메라를 이용해 좌/우측에 이미지가 들어오는 경우에는 차량의 steering 을 조정하도록 한 방식은 잘 도로를 따라갈 수 있었다. 또한, 이전에서는 mistake 가 생기면 관측하지 못한 새로운 환경에 놓였던 문제를 data 를 augment 하여 해결하였다.
Why does behavioral cloning fail? A bit of theory
어떻게 해야 학습된 를 좋게 만들 수 있을까?
학습한 action 의 likelihood 를 최대화 하는 것은 아닐 것이다.
이렇게 하면 운전자가 실제로 보았던 observation 에서 취했던 action 에 높은 확률분포를 할당하게 되고, 이는 약간의 다른 상황에서 mistake 를 유발한다.
그래서 우리는 아래와 같이 cost 함수를 정의해볼 수 있다.
취한 action 이 운전자가 취했던 action 과 동일하면 cost 를 0으로 하고, 이 외에 경우에는 1로 두는 것이다. 이 경우 운전자가 deterministic policy 임을 가정한다.
쉽게하자면, mistake 를 일으키면 cost 를 받게되는 것이다.
이제 목표는 state 의 확률 분표에서 기대되는 cost 를 최소화 하는 것이다.
Some analysis
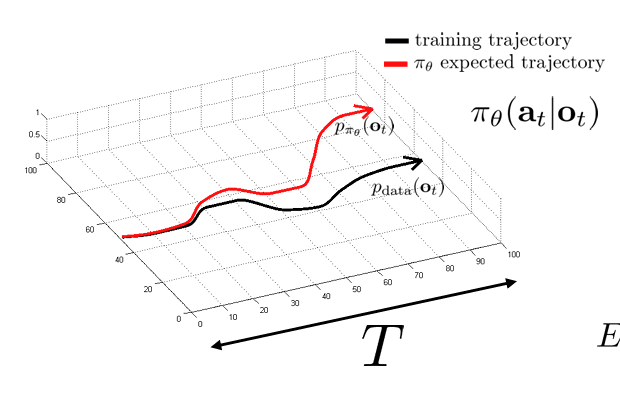
전체 horizon 시간을 라고 하자. 그리고 학습된 state 라면 () 운전자와 다른 action 을 취할 확률을 이하라고 하자.
그렇다면 외줄타기처럼 굉장히 좋지 않은 결과가 나타날 것이다.
한 번의 mistake 를 저지르면 더이상 운전자가 보았던 state 에 있지 않기 때문에 더이상 어떻게 할지 모르기 때문이다.
이는 cost 가 unbounded 되어 있는 확률이기 때문에 전체 cost 에 대해 bound 를 설정해주어야 한다.
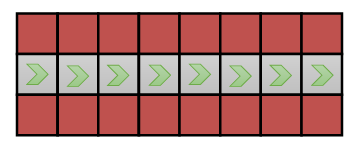
첫 블록에서는(첫 번째 timestamp) 적어도 의 mistake 를 저지르게 될 것이다. mistake 를 저지르지 않으면 다음 블록으로 넘어가게 되고, 이러한 과정이 반복되며 급수를 구성할 수 있게 된다.
각 가 개 있으므로 전체 order 는 가 된다. 이는 최악에 경우, 시간이 지남에 따라 quadratic (제곱)으로 실수를 저지를 확률이 올라감을 의미한다.
More general analysis
이제 모든 state 가 training set 에 있는 것()이 아니라 training set 의 확률 분포로부터 샘플링되었다고 하자.
그러면 기댓값을 계산하는 것으로도 충분하고 더 현실적인 접근이다.
DAgger 를 사용하면 로 만들어주고 를 얻게된다.
만약 인 경우에는 mistake 를 저지르지 않을 확률과 저지를 확률로 나뉘게 된다.
첫 번째 term 은 구하기 쉽지만 두 번째 term 의 는 꽤 복잡하다.
이제 아래 수식이 잘 이해되지 않았다. 각 확률 분포의 최대 차이를 모든 state 에 대해 더하면 2 여서 다음과 같이 정리된다고 한다.
를 이용하면 결국 는 이하가 된다.
이를 바탕으로 우리가 진짜 살펴보고 싶은 cost 의 기댓값을 알아보자.
모든 에서 취할 action 의 cost 를 모두 더한 것을 수식으로 표현한 것인데, 를 로 바꾸고 와 의 곱을 바깥으로 빼내어 bound 를 구해보자.
전제조건과 위해서 구해놓은 부등식으로 바로 얻어낼 수 있다. 이를 에 대해 계산해주면 이 된다.
결론적으로는 마찬가지로 의 시간복잡도가 됨을 알 수 있다.
왜 이런 좋지 않은 결과가 나타날까? Imitation learning 에서는 mistake 를 다시 복구하는 방법을 배우지 않기 때문이다.
만약 학습한 state 의 분포가 더 넓다면, 약간의 mistake 를 하더라도 여전히 이러한 분포 안에 있을 것이므로 조금 더 잘 배운대로 나아갈 수 있을 것이다.
여기에서 생기는 모순점은 imitation learning 이 데이터가 mistake 를 같이 가지고 있을 때 더 좋은 성능을 낼 수 있다는 것이다.