Lecture 2. Imitation Learning Part 3 ~ Lecture 3. PyTorch
Lecture 2. Part 3
https://rail.eecs.berkeley.edu/deeprlcourse/deeprlcourse/static/slides/lec-2.pdf
Addressing the problem in practice
앞서 behavioral cloning 에서 발생한 문제들을 실제로는 어떤 식으로 해결하는지 다뤄본다.
앞서 작은 mistake 가 생기면 어떻게 해야할지 모르는 문제로 인해 mistake 이 누적되고 결국에는 큰 차이가 생겼다고 언급했었다.
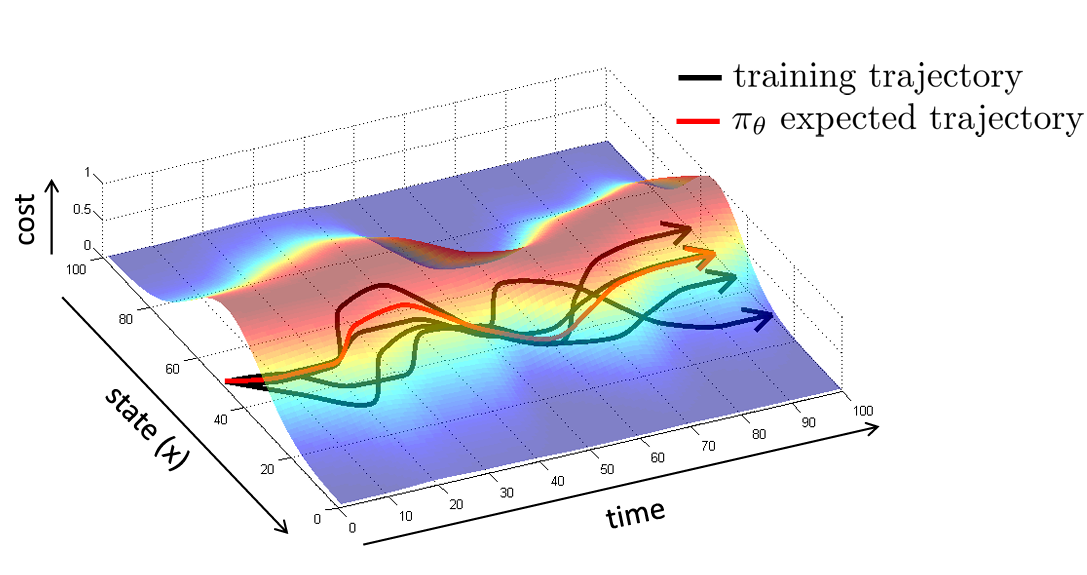
Be smart about how we collect (and augment) our data
학습 데이터에 mistake 가 포함되어 있다면, 이를 수정하는 방법을 알려줄 수 있을 것이다. 그래서 의도적으로 mistake 와 수정사항을 데이터셋에 넣을 수도 있다. (물론 데이터셋이 좋지는 않지만 오히려 수정사항이 더해져 있는 것이 좋은 경우도 있음.)
또 다른 방법은 data augmentation 이다. 가짜 데이터를 추가하여 위와 유사한 효과를 얻을 수 있다.
- Case study 1: trail following as classification: 사람이 직접 정면, 좌/우측면 카메라를 장착하고 숲속을 거닌 데이터를 활용
- Case study 2: imitation with a cheap robot
Use very powerful models that make very few mistakes
데이터를 잘 다루는 것도 중요하지만 이것만으로 충분히 신뢰할 수는 없고, 근본적인 원인을 해결할 필요성이 있다.
Why might we fail to fit the expert?
본질적으로 왜 전문가의 행동과 일치하게 만들기 어려운지 알아보자.
- Non-markovian behavior
우리가 구성한 policy 는 현재의 observation 를 기반으로 한다.
하지만 실제로 전문가가 어떤 행동을 할 때는 이전에 진행한 내용들을 모두 기억하고 행동을 취한다. 우리의 policy 에 따르면 이전에 어떤 일이 일어났는지와 관계없이 같은 것을 본다면 같은 행동을 하도록 되어있고, 이는 매우 부자연스럽다.
How can we use the whole history?
여러 개의 프레임을 사용하여 이전의 기억(history of observation)을 포함할 수 있는 policy 를 세운다. 이를 처리하기 위해 sequence model 을 활용한다. (Transformer, LSTM cells, etc.)
이러한 방식도 잘 작동하지 않을 수 있다. 여러 프레임을 사용하여 학습을 하기 때문에 사건에 따라 각 프레임 간의 상관관계를 잘못 파악하는 causal confusion 이 생기는 것이다.
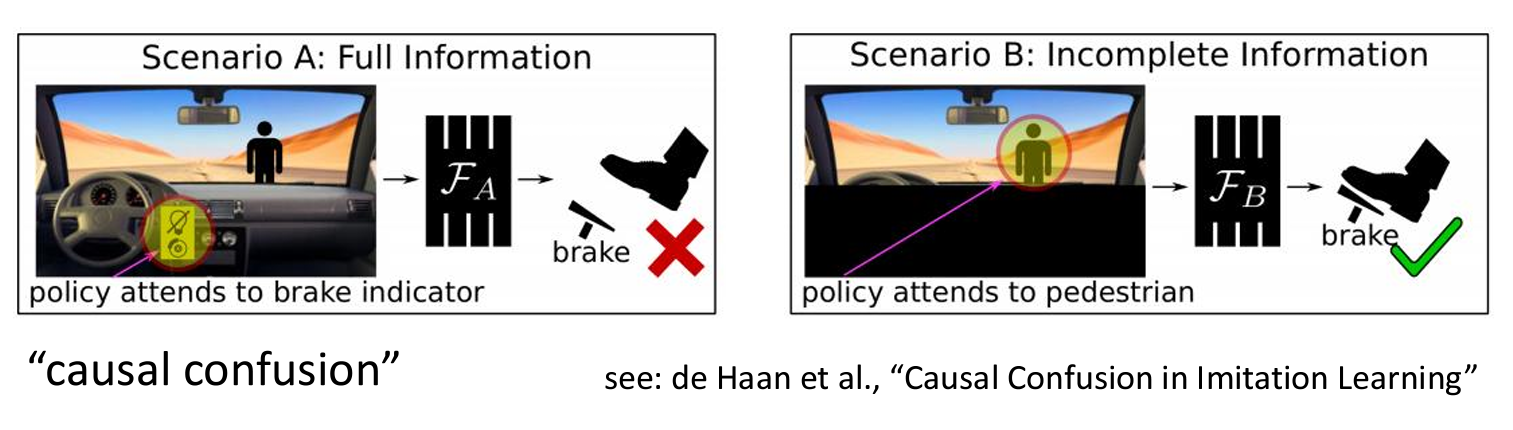
강의에서는 브레이크 표시등과 전면부가 같이 있는 이미지를 예시로 들었다. 만약 사람이 나타나서 브레이크 표시등이 켜졌다면, 이것은 표시등이 원인이 아니라 사람이 나타난 것이 진짜 원인이다.
그러나 이후에 표시등이 계속 켜지면서 모델은 표시등과 감속 간의 인과관계에 집중하게 된다. 그래서 이러한 방식은 보조장치와 진짜 원인과 혼동을 야기하고 잘못된 상관관계를 유도할 수 있다.
Question
- Q 1: Does including history mitigate casual confusion?
- Q 2: Can DAgger mitigate causal confusion?
- Multimodal behavior
왼쪽, 오른쪽과 직선과 같이 이산적인 판단을 내릴 때는 문제가 되지 않지만 연속적인 행동을 수행할 때는 문제가 있다.
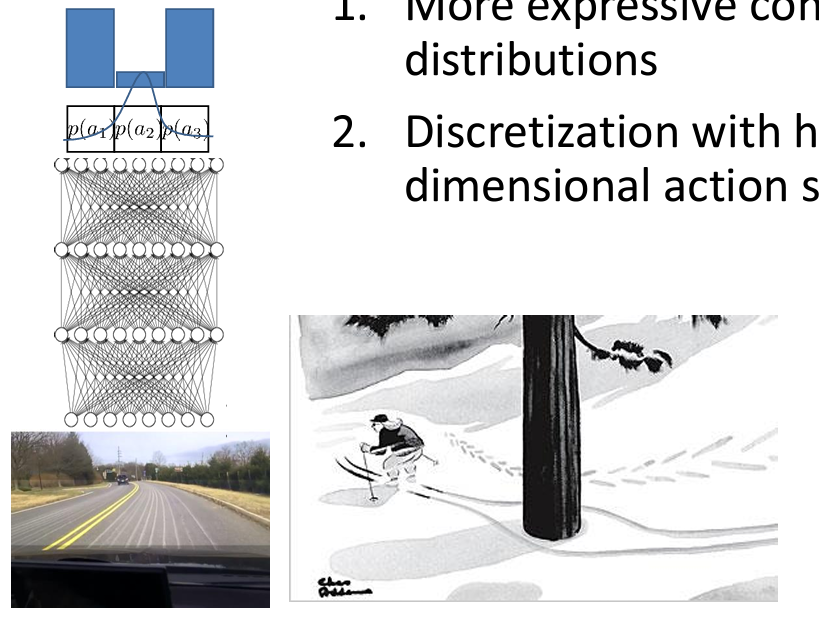
위와 같이, 직선을 제외한 좌우측으로 이동해야 하는 경우 출력을 가우시안 분포로 표현하면 하나의 평균과 분산으로 이루어져 있기 때문이다.
그래서 연속적인 분포를 설명가능한 다른 방식을 사용하거나, 이산화를 여전히 사용하되 더 고차원의 공간에서 사용하는 방법이 있다.
Expressive continuous distributions
- Mixture of Gaussians
- Latent variable models
- Diffusion models
discretization
이산화는 복잡한 분포를 표현하는데 좋은 방법이지만 고차원의 space 를 이산화로 바로 표현하는 것은 어렵다.
왜냐하면 차원이 높아질 수록 표현해야 하는데 필요한 구간의 수가 기하급수적으로 늘어난다.
따라서, 한 번의 한 차원만 표현하는 autoregressive discretization 을 사용한다.
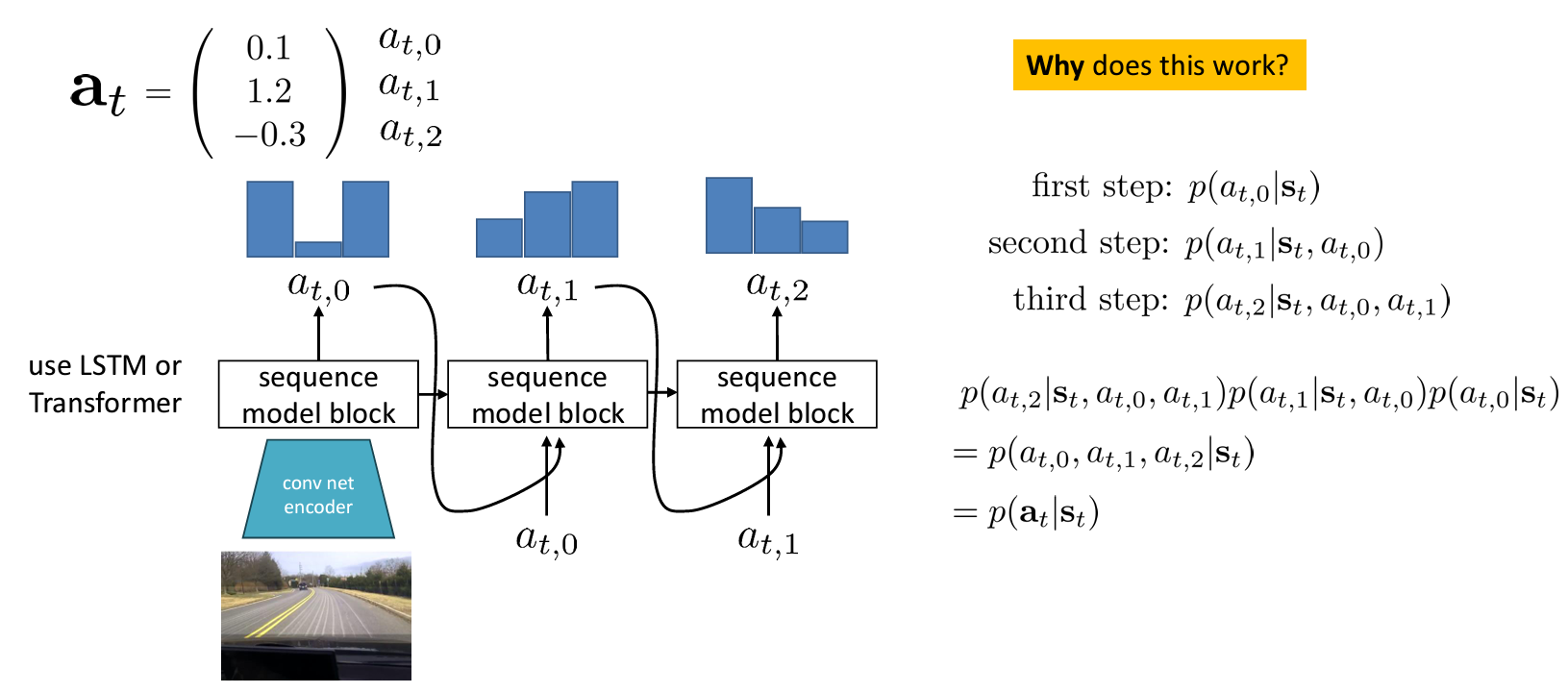
LSTM 이나 Transformer 와 같은 sequence model 로 인코딩하여 이산화된 결과를 얻으면 이를 연속적으로 넣어 다음 예측을 얻어낸다.
이를 수식적으로 표현하면 결국 모든 에 대한 확률분포를 얻기 때문이다. 따라서 autoregressive discretization 는 매우 좋은 방식이지만 무겁다는 단점이 있다.
- Case study 3: imitation with diffusion model (Chi et al, Diffusion Policy: Visuomotor Policy Learning via Action Diffusion)
- Case study 4: imitation with latent variable (Zhao et al. Learning Fine-Graned Bimanual Manipulation with Low-Cost Hardward)
- Case study 5: imitation with Transformeres (Brohan et al. RT-1: Robotics Transformer), transfomers를 활용한 discretization 방법
Use multi-task learning
Does learning many tasks become easier?
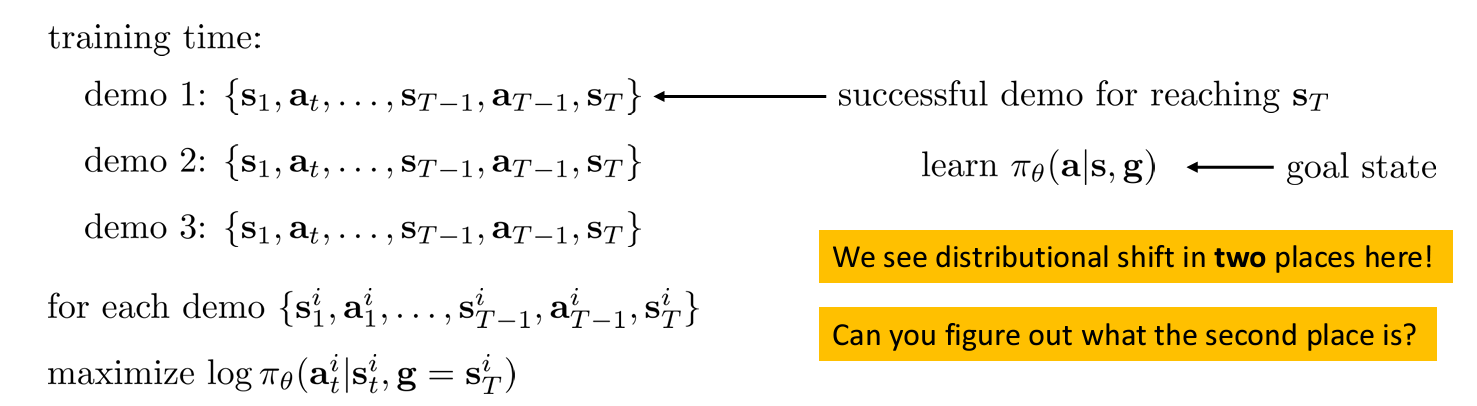
이전처럼 하나의 위치 을 도달하기 위한 전문가의 학습 데이터를 구성하는 것이 아니라 여러 개의 를 도달하는 과정을 학습하는 것이다.
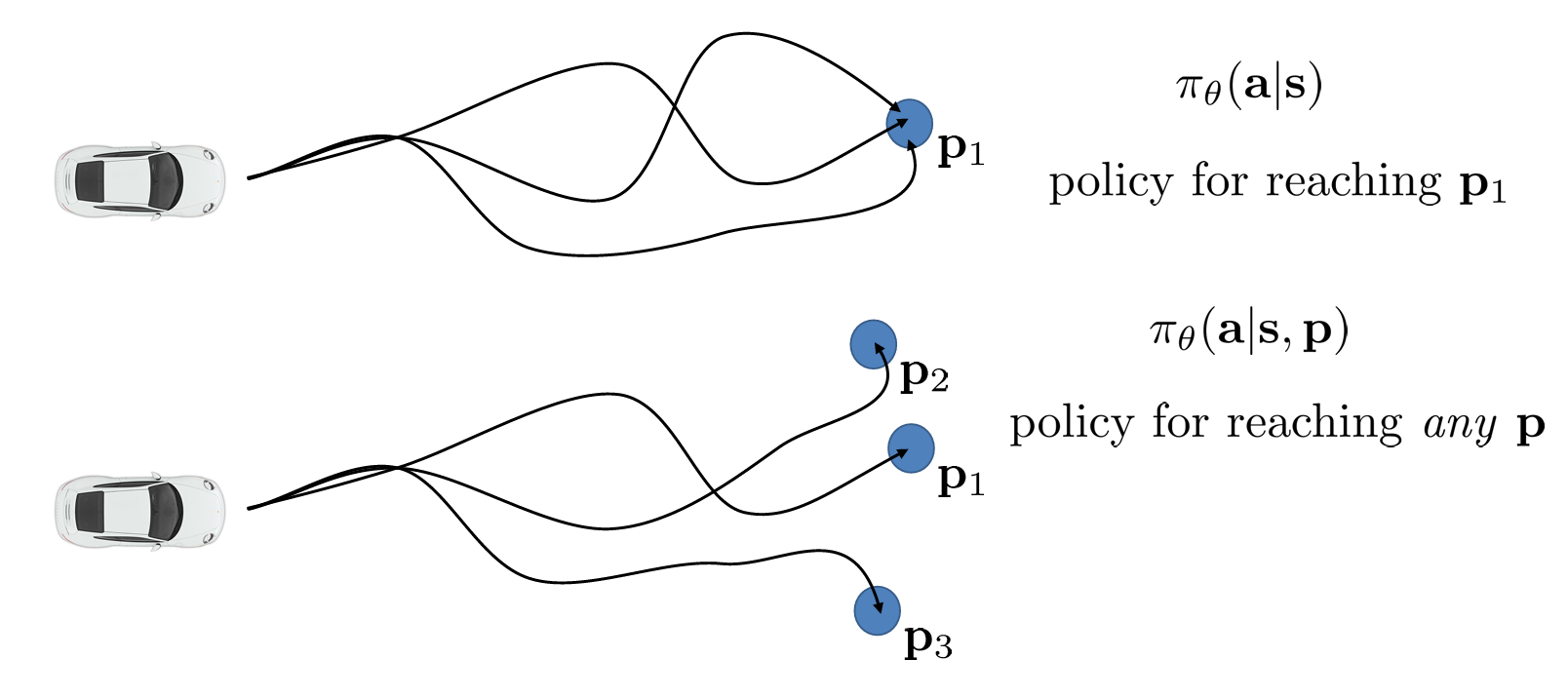
이러한 방법은 의도적으로 실수를 넣거나 augmentation 없이 다양한 state 에서 데이터를 얻을 수 있게 된다. 즉, 전문가가 으로 가기 위한 최적의 경로에서 방문하지 않은 다른 state 들이 다른 를 도달하기 위한 경로에서 얻게 되는 것이다.
Related works
- Learning Latent Plans from Play, C. Lynch et al. Google Brain
- Unsupervised Visuomotor Control through Distributional Planning Networks, Yu, Tianhe, et al.
- Learning to Reach Goals via Iterated Supervised Learning, D. Ghosh et al., UCB
- GNM: A General Navigation Model to Drive Any Robot, Shah et al.
- Hindsight Experience Replay, Marin Andrychowicz et al., OpenAI
Change the algorithm (DAgger)
앞서 학습한 경로와 가 진행한 경로가 차이났던 것을 분포 이동의 문제로 설명할 수 있다. 즉 와 가 다르다는 것이다.
그렇다면 policy 를 수정하는 (이전의 내용)대신 데이터를 수정하여 을 만들 수 있을까?
DAgger 가 이 문제에 대한 답을 얻기 위한 방법이다.
DAgger (Datset Aggregation)은 policy 를 실제 환경에서 수행해서 state 가 어떻게 바뀌는지 보고, 직접 사람들에게 라벨링을 요청하는 것이다.

이렇게 를 계속 수행하여 유사한 분포를 가지게 되며 의 분포가 데이터 세트를 지배하게 된다.
DAgger 의 문제점은 사람이 직접 라벨링하는 것이 일이 일어난 후에 검토하는 것이므로 부자연스럽고, 매 순간 빠르게 결정을 내려야 하는 경우에 모든 것을 다시 라벨링하므로 해결하긴 어렵다.
어쨌든 추가적인 데이터를 얻을 수 있다는 강한 전제 하에 의 선형적인 복잡도를 가질 수 있게된다.
Lecture 3. PyTorch Tutorial
https://rail.eecs.berkeley.edu/deeprlcourse/deeprlcourse/static/slides/lec-3.pdf
https://colab.research.google.com/drive/12nQiv6aZHXNuCfAAuTjJenDWKQbIt2Mz
RL Connection: You would want to be doing simulator-related tasks with numpy, convert to torch when doing model-related tasks, and convert back to feed output into simulator.